
Churn is just graduation you didn't design for.
Cabinet, Mem, and NotebookLM show what happens when a personal knowledge base hits its ceiling.


If you’ve spent the last few months building a personal knowledge base, you probably know this feeling. The first week is extraordinary. You drop a few documents in, you ask a question, the AI synthesizes an answer that would have taken you an hour to produce manually. You restructure your whole capture workflow around it. It feels like you’ve finally solved the information problem.
Then six weeks in: your archive grows, your use cases multiply. And somewhere around the third month, the thing you built for yourself stops scaling with you - turning into a bloated mess over time - and you’re not sure if the problem is the tool or the system or just you. Hard to imagine we ever built personal knowledge management systems that felt this good to start, and this frustrating to maintain.
That wasn’t always the case.
In the 2000s, personal knowledge management wasn’t a product category. It was a practice - and a fairly elite one. The people who built serious personal archives were academics, researchers, and a small group of methodological obsessives who had discovered Niklas Luhmann’s Zettelkasten method and committed their careers to replicating it. Everyone else kept bookmarks, email folders, and the occasional Word document labeled “notes - important.” Memory was personal and fragmented, and nobody expected technology to fix it.
The first wave of mass-market change came with Evernote. Capture became easy. The problem, quickly obvious, was that easy capture creates a different crisis: retrieval. By 2015, the average Evernote user had thousands of notes they couldn’t find. Evernote had solved the input problem and created the organization problem in its place.
Notion and Obsidian arrived with better answers to organization, and built devoted communities around the idea that a well-structured personal archive was worth investing in. The PKM (personal knowledge management) community that grew up around these tools in the early 2020s was genuinely influential - YouTube channels dedicated to note-taking systems attracted millions of views. The practice became a philosophy. The philosophy became a market.
Then AI note-taking arrived and seemed, briefly, to solve the problem from a different angle. Tools like Granola and Coconote stopped asking users to organize at all - they attended your meetings, transcribed your conversations, and surfaced structured summaries automatically. If you haven’t read the piece on why AI note-taking tools no longer compete on features, the short version is this: those tools solved the capture problem elegantly, but treated knowledge as infrastructure rather than something that compounds. Once the meeting ended, the value was mostly extracted.
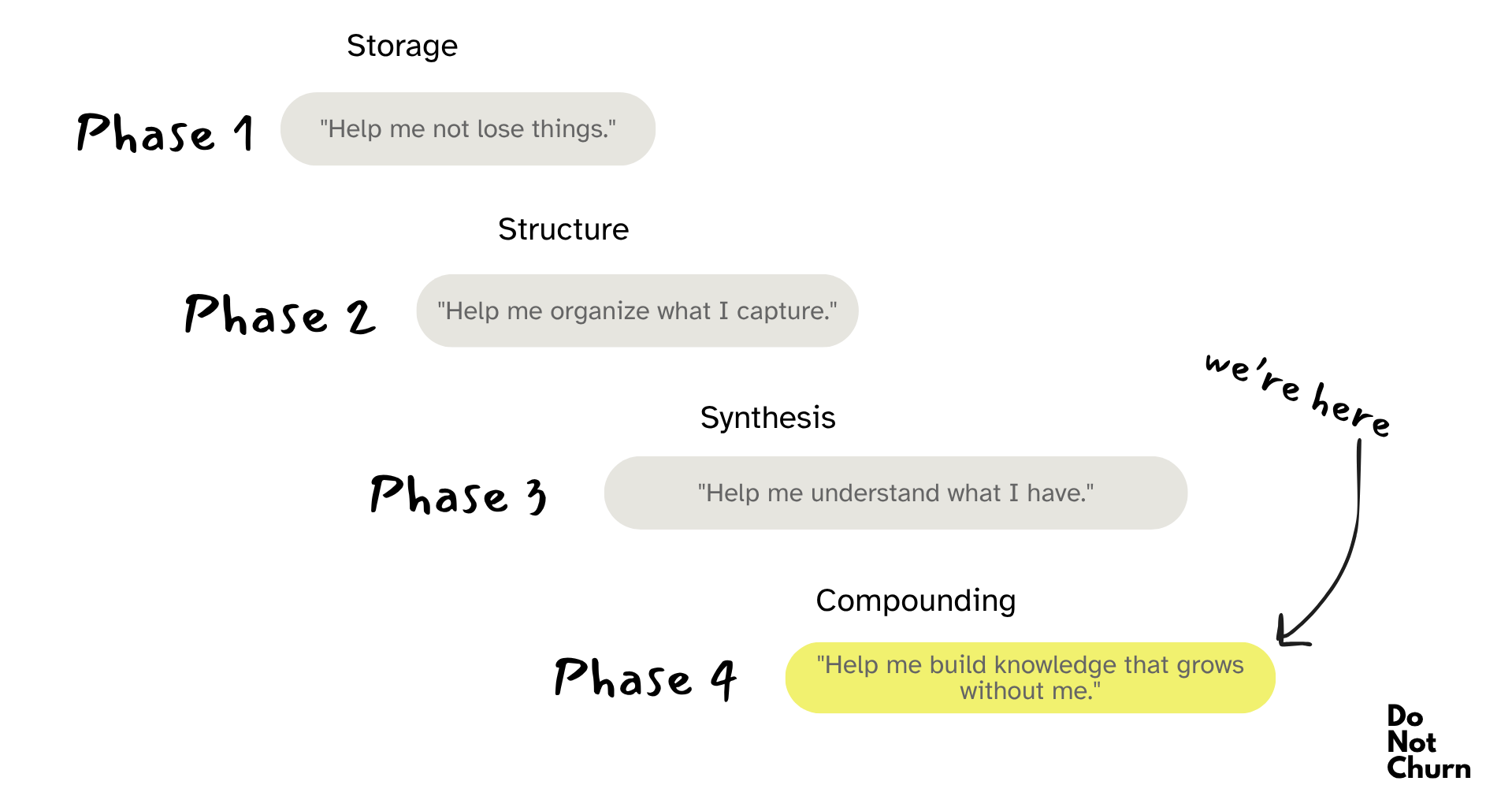
And yet the failure mode persisted. The people who maintained elaborate systems were the people who had time and inclination to do so - a narrow subset of knowledge workers. For everyone else, the system became a second job at exactly the moment their first job got busier.
The real shift is happening now: when Andrej Karpathy posted a GitHub gist in April 2026 that described what he called “LLM Knowledge Bases” - a pattern where the AI doesn’t just answer questions from your archive, it compiles and maintains the archive itself. The post reached 16 million views in 48 hours. He basically named the actual failure mode everyone had been living with: knowledge systems fail not at setup, but at scale.
In reality, that failure reflects something more structural:
The churn event in personal knowledge tools is not abandonment. It is the moment the tool stops being able to grow with the problem it was hired to solve.
Personal knowledge base tools replaced bookmarks, then replaced folders, and now they’re replacing the act of organizing knowledge at all.
Cabinet, Mem, and NotebookLM are not variations of the same product. They are answers to different theories about where in the scaling curve a user actually needs help - and each one reveals something distinct about how churn operates when the problem grows faster than the tool designed to solve it.

Cabinet is optimized for what I’d call autonomous compounding - a system where the knowledge base writes itself, continuously, without the user’s active participation.
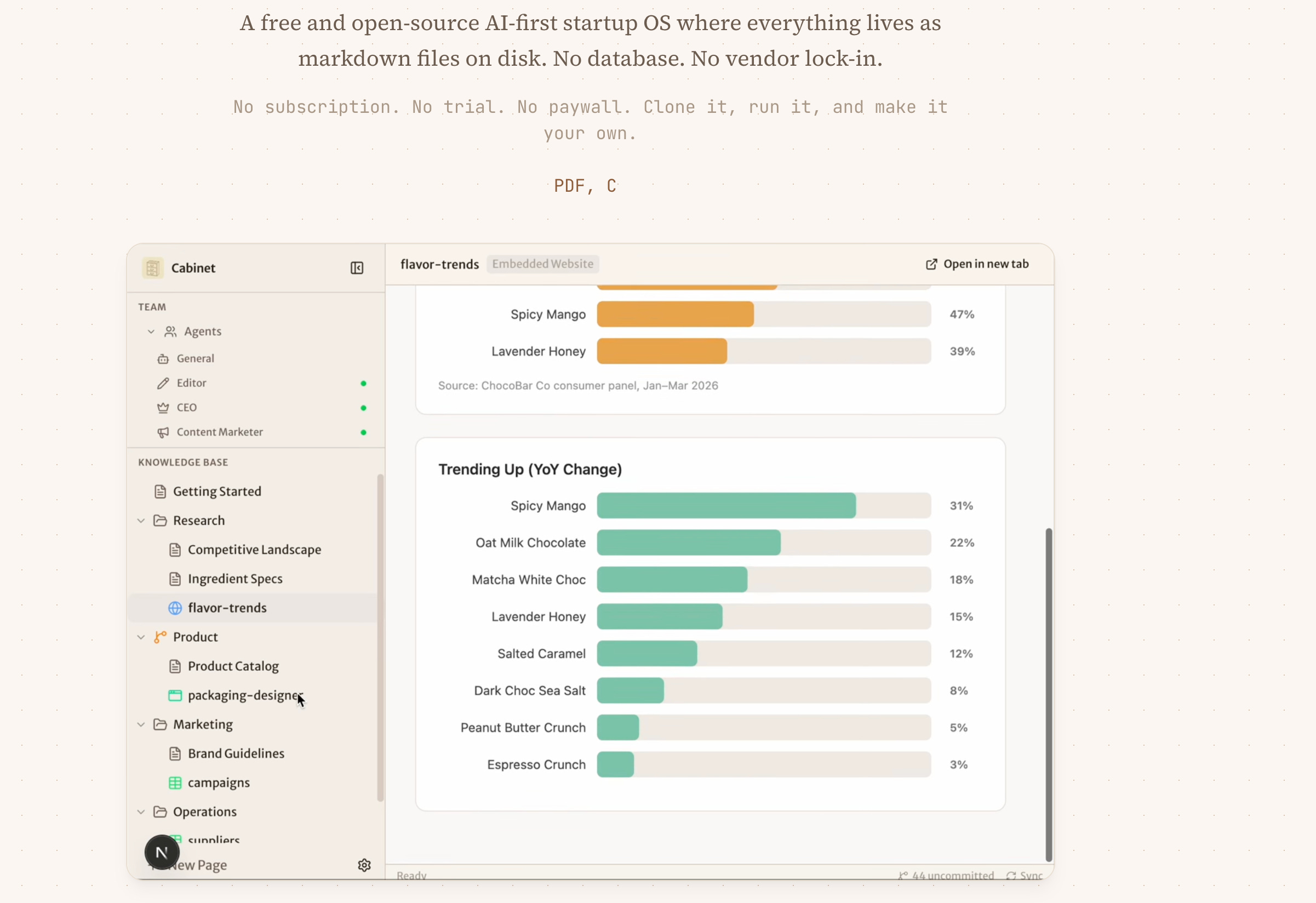
Hila Shmuel is a former Engineering Manager at Apple who left to build Cabinet in public, with the open-source community. The thesis was personal: every time she started a new Claude session, it forgot everything - her project context, her decisions, her research. Cabinet was her answer to that. Launched in 2026, it’s free, self-hosted, and built on the belief that your AI context should live on your machine - not in a vendor’s cloud. The tagline says it plainly: one knowledge base, AI agents that remember everything.
Primary intent: Persistent operational memory
Job it does:
“I need my AI to know what I know, remember what I’ve decided, and keep building on it while I’m doing other things. And… I don’t want to re-explain my context every time I open a new session.”
It translates to:
Install locally
Onboarding wizard builds agent team
Agents run on cron schedules
Agents write structured entries to the KB
Context compounds across all sessions
User queries a KB that grows without prompting
Best for:
Technical founders running lean
Solo operators managing multiple products
Builders who want agents as coworkers, not assistants
Anyone whose AI sessions currently feel like amnesia
Cabinet nailed that the problem isn’t accessing a knowledge base - it’s maintaining one. Every other tool in this category implicitly requires the user to do something: clip this, tag that, organize the other. Cabinet’s design thesis is that a system you have to tend is a system you will eventually abandon. The agents do the tending. You do the steering.
Cabinet intentionally ignores mobile experience, non-technical users, and cloud-first deployment. It treats the knowledge base as infrastructure that agents read and write to, not an interface that humans browse. The human’s relationship to the KB is interrogative, not editorial.
The strongest thing Cabinet does is eliminate the maintenance bottleneck entirely. In every other PKM system, the failure mode is predictable: users set up the system in a burst of enthusiasm, use it well for three to six weeks, get busy, stop maintaining it, and return six months later to an archive that feels stale and untrustworthy. Cabinet’s automated agents break this cycle structurally — the KB continues updating regardless of whether the user is paying attention. This is not a feature. It is a different theory of what a knowledge system is.
The compounding mechanism is also real in a way that most tools only promise. A Reddit scout running every six hours doesn’t just collect links — it deposits structured, synthesized intelligence into a KB that cross-links with everything already in it. At month six, the KB contains institutional memory that no single document could hold.
Churn Watch: When agent output quality degrades, or agents start producing noise rather than signal, the trust in the KB erodes. Unlike manual systems, where the user controls what goes in, Cabinet’s automated writes mean garbage-in-garbage-out is invisible until the KB feels unreliable. Cabinet needs a quality signal - some way for users to see whether agent outputs are being used, or quietly accumulating unread.
When retention depends on automated compounding, the winning strategy is not more automation - it’s auditable automation.
About this newsletter:
I’m Daria Littlefield. I spent a decade running customer operations across 35+ dating and social apps - the kind people delete in a rage and reinstall a week later. That taught me more about why products lose users than any framework ever could. Do Not Churn is where I put that to use. Every week, I break down the retention mechanics behind the products we all use - what keeps people, what loses them, and why the difference is rarely what you’d expect. If that’s useful to you, subscribe below.
If you’ve ever watched your metrics show healthy retention while your best users stopped doing the thing they originally signed up for - share it with me in comments.

Mem is a zero-folder knowledge management product built for people who capture more information than they can organize. Mem nailed that the output of note-taking is not notes, but accessible, connected knowledge - and that the act of organizing is the thing most people will not do.
Kevin Moody and Dennis Xu met as college freshmen in San Francisco in 2014, eating Korean fried chicken and talking about why digital storage systems seemed to do the opposite of human memory - information captured into them fragmented instead of compounding. Seven years later, they launched Mem with backing from a16z and, in 2022, a $23.5M Series A led by the OpenAI Startup Fund. The founding mission hasn't changed: build the world's first self-organizing workspace, where the AI handles organization so the human never has to.
Primary intent: Frictionless accumulation
Job it does:
“I capture everything and organize nothing - and I need an AI to make that archive useful anyway. And I don’t want to build a taxonomy that I’ll abandon in three months.”

It translates to:
Capture freely, any format
AI auto-organizes and tags
Related Mems surface contextually
Mem Chat synthesizes on demand
Smart Write drafts content from your history
Best for:
Consultants and knowledge workers who capture in bursts
Researchers who accumulate faster than they process
Writers who want a second brain that writes back
Professionals who’ve abandoned every PKM system they’ve tried
Mem fixes what Notion and Obsidian leave behind: the organizational debt. Both of those tools give you a powerful structure - and then require you to maintain it. Mem bets that the AI should absorb the organizational burden entirely. The user’s job is to capture. The system’s job is to make the capture retrievable.
Mem’s strongest feature is the one that’s hardest to describe in a demo: the feeling, after three months of active use, that the archive is smarter than you are. Mem Chat doesn’t just retrieve notes - it surfaces conceptual bridges between ideas you captured months apart and never consciously connected. The user who asks “What do I know about why early SaaS products fail?” gets a synthesis that draws from five different notes taken in five different contexts. That synthesis is genuinely novel. It’s not a search result.
The Smart Write function is Mem’s most underrated retention anchor. When the AI can draft content that sounds like you — because it’s drawing from your accumulated voice, your preferences, your past positions — the switching cost becomes real in a way pure note-taking tools never achieve. Your voice is in the KB now.
Churn Watch: Mem’s churn risk arrives precisely when the KB reaches critical mass. The zero-structure philosophy works elegantly at low volume. At high volume - thousands of notes, years of capture - users start to feel that the AI organization is serving the system rather than serving them. The problem that its organizing logic becomes opaque at scale. Users who built elaborate Notion systems and felt the organizational debt creep in have a muscle memory response to that feeling: they start looking for the exit.
The second churn vector is data trust. Mem can only be as useful as what you’ve put into it - which means gaps in capture create gaps in synthesis. Users who go through three weeks without capturing anything return to an archive that feels stale, and they blame the tool rather than the habit. Mem needs a gap-awareness layer - something that surfaces what’s missing from the archive, not just what’s in it.
When retention depends on accumulated capture, the winning strategy is not more intelligent retrieval - it’s making the cost of not capturing visible.

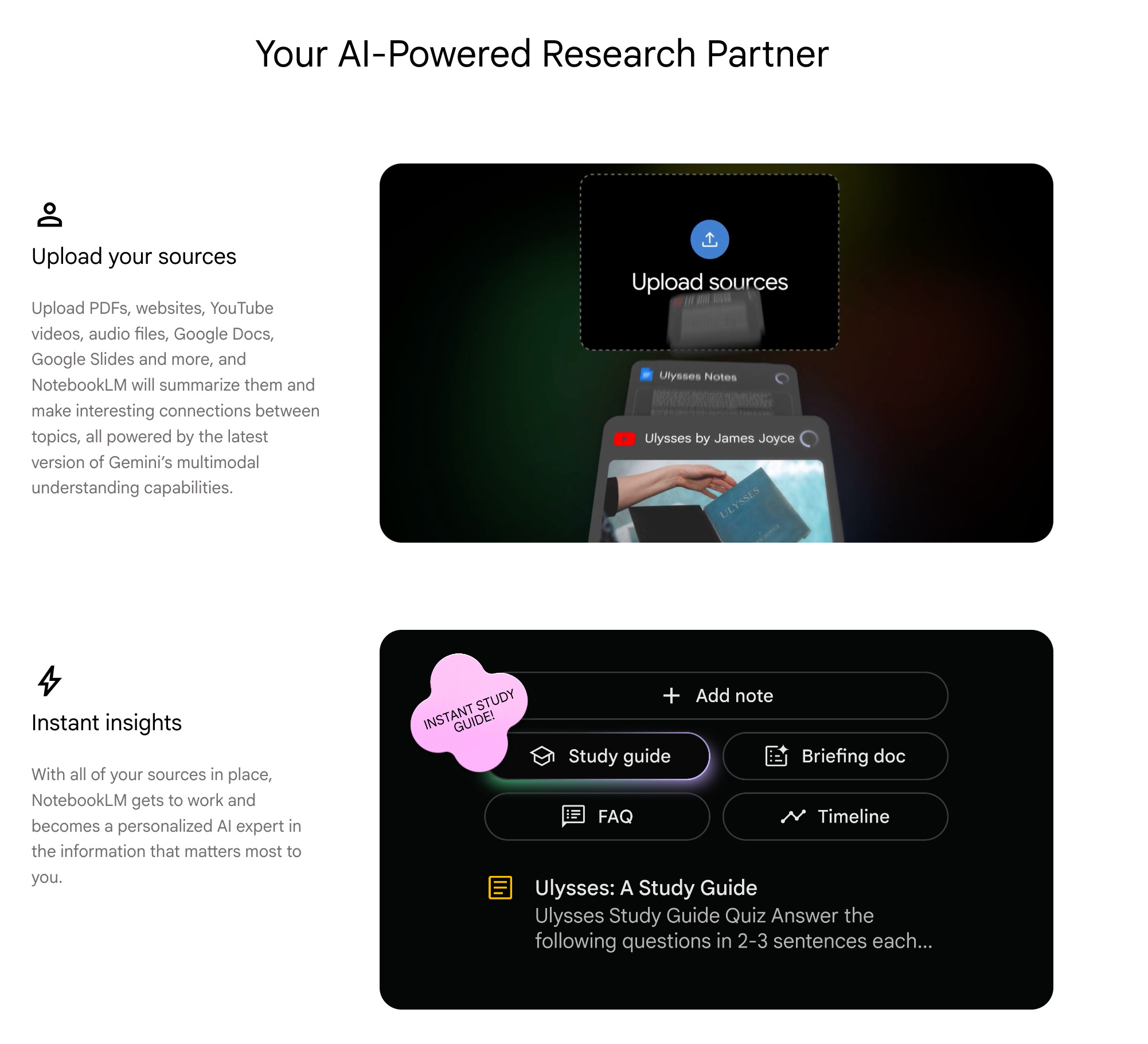
NotebookLM is a source-grounded research assistant designed to let users interrogate a defined body of material without reading every word. It doesn’t try to build a long-term archive, it doesn’t try to remember across projects, it doesn’t try to write to itself.
NotebookLM started as a research project inside Google Labs in 2023, originally called Project Tailwind. The core idea came from author Steven Johnson, who joined the team early: build an AI that helps you understand things - not the internet, not general knowledge, just the specific documents you’ve chosen to work with. It launched publicly in 2023, reached tens of millions of users without a marketing budget, and became Google’s quiet answer to the question of what AI-native research actually looks like. By 2026 it connects directly to Google Gemini, turning your notebooks into a persistent context layer across your entire Google workspace.
It tries to be the fastest path from a pile of documents to a usable understanding.
Primary intent: Project-scoped synthesis
Job it does:
“I have forty PDFs and twelve links and a week before this matters. Help me understand all of it without reading all of it.”
It translates to:
Upload sources (PDFs, URLs, YouTube, docs)
AI generates source map and summary
Natural language query against sources
Generate Audio Overview, mind map, flashcards
Export insight for use elsewhere
Best users:
Students preparing for exams or papers
Researchers synthesizing literature for a project
Analysts doing competitive or market deep-dives
Operators onboarding into a new domain quickly
NotebookLM fixes what document overload leaves behind: the two days of reading you don’t have. It is source-grounded by design - responses are anchored to what you uploaded, not what the model knows generally, which means answers are traceable and hallucinations are structurally constrained.
NotebookLM’s best design decision is also its most unusual: it doesn’t try to be a permanent brain. Each notebook is a project. The sources are scoped. The value is extracted. And then you move on. This is the exact opposite of the Karpathy pattern - and it is the right answer for a significant portion of knowledge work that isn’t about compounding but about sprinting through a defined body of material.
The Audio Overview feature has no real equivalent in the market. The ability to generate a conversational podcast from your uploaded documents - and then interrupt the hosts mid-sentence to ask clarifying questions - is a genuinely different cognitive interface. Users who learn through listening, or who process information while commuting, have found something in NotebookLM that nothing else offers.
Churn Watch: NotebookLM’s churn risk is structural and, in an important sense, by design. The notebook model means that knowledge doesn’t compound — each project is an island. Users who start with a scoped research task and then want to build a growing personal KB will hit the ceiling of what NotebookLM was built to do. The tool doesn’t grow with them. It doesn’t remember what they uploaded last month or cross-reference the current notebook against previous ones.
This is not a failure, but a positioning decision. But it creates a predictable churn moment: the user who graduates from “I need to understand this report” to “I need a system that builds on everything I’ve ever learned” will churn from NotebookLM toward Cabinet or Mem. NotebookLM’s retention strategy should not try to prevent this transition - it should own the project-scoped lane completely and build deeper into it.
When retention depends on task completion, the winning strategy is not accumulation - it’s becoming indispensable to the sprint.
6 retention mechanics to steal
1. Build compounding, not resetting. If your product’s value resets when a session ends, your retention depends entirely on the next session starting. That’s a fragile place to be. The tools that keep users longest are the ones whose value at month six is structurally higher than at month one - not because of new features, but because of what accumulated. Design for accumulation. Every interaction should leave something behind.
2. Solve maintenance or lose the busy user. The knowledge management graveyard is full of tools people loved during onboarding. The failure mode is always the same: maintenance debt builds during a busy period, the user stops tending the system, returns to find it stale, and leaves. If your product requires active upkeep to stay valuable, you’re asking users to work hardest for you exactly when they have the least capacity. Automate the maintenance, scope it away, or watch it become your churn trigger.
3. Know where your product stops working. The most invisible churn event isn’t frustration - it’s graduation. Users don’t cancel; they quietly stop using your product for the job they’ve grown into, while technically remaining subscribers. You won’t see it in your cancellation data. You’ll see it in engagement collapse three months before the cancel. Every product has a scope ceiling. The question is whether you know where yours is and whether you’ve designed anything for the moment users hit it.
4. Trust in AI-organized data is fragile and non-negotiable. The moment a user catches your AI getting something wrong - a synthesis that feels off, a gap that should have been filled - the trust relationship with the entire archive cracks. This is not a bug report. It’s a churn signal. Users don’t need perfection, but they need to believe the system is reliable enough to depend on. One bad retrieval at a critical moment undoes months of compounding goodwill.
5. The users hardest to lose are the ones who’ve gotten the most value. Switching costs in compounding systems don’t scale with subscription length - they scale with accumulated value. A user who has two years of captures in Mem isn’t just paying $15/month; they’re sitting on an archive that would take two years to rebuild. That asymmetry is your deepest moat, and most products never deliberately design for it. Ask yourself: what does a user have after one year that they couldn’t easily recreate somewhere else?
6. Tell users before they hit the ceiling. The churn event at the scale transition is usually not inevitable - it happens because the product never warned the user it was coming. If you know your product works brilliantly up to a certain scale and starts to strain past it, build the signal that says so. Offer the path forward before the user discovers the wall in frustration. The product that says “you’re outgrowing this - here’s what’s next” retains more than the one that quietly fails and waits to be abandoned.
Personal KB tools didn’t converge into a single super-tool but split along lines of where in the user’s scaling curve they were designed to be useful.
Some tools exist to synthesize a bounded problem fast. Others exist to accumulate and organize without demanding maintenance. Others exist to compound institutional memory autonomously, indefinitely.
Churn emerges not when a product fails at its original job, but when the user’s job grows beyond what the product was designed to handle - and the product has no answer for what comes next.
In personal knowledge management, retention grows when the tool scales with the problem it was hired to solve. A knowledge base remains valuable only if the depth it offers today is not the ceiling it will hit tomorrow.
Key takeaways:
Personal KB tools compete on scale tolerance, not intelligence - the question is not which tool is smarter, but which tool can grow with the user who hired it.
Project-scoped tools like NotebookLM retain users by becoming indispensable to the sprint; their churn event is structural graduation, not dissatisfaction.
Accumulation-first tools like Mem retain users through compounding capture value, but face a trust collapse when the AI organization becomes opaque at high volume.
Automation-first tools like Cabinet eliminate the maintenance bottleneck entirely - their churn risk lives at setup friction and agent output quality, not at feature gaps.
The most important churn event in this category is invisible in standard metrics: the user who silently stops using a tool for the job they’ve scaled into, without ever formally churning from the job they started with.